

vue 双向绑定原理 【原理题】
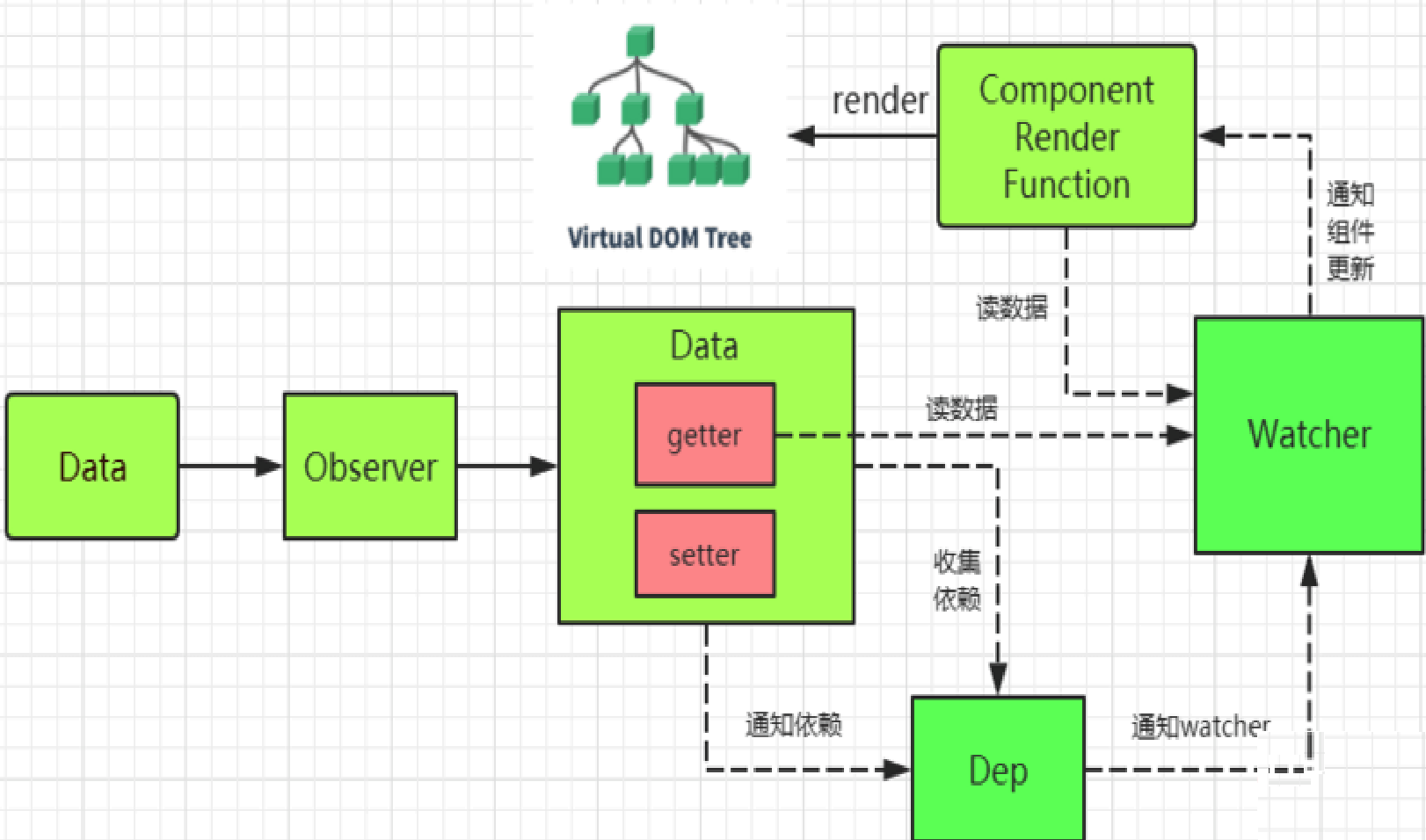
核心实现类:
Observer : 它的作用是给对象的属性添加 getter 和 setter,用于依赖收集和派发更新
Dep : 用于收集当前响应式对象的依赖关系,每个响应式对象包括子对象都拥有一个 Dep 实例(里面 subs 是 Watcher 实例数组),当数据有变更时,会通过 dep.notify()通知各个 watcher。
Watcher : 观察者对象 , 实例分为渲染 watcher (render watcher),计算属性 watcher (computed watcher),侦听器 watcher(user watcher)三种
Watcher 和 Dep 的关系
watcher 中实例化了 dep 并向 dep.subs 中添加了订阅者,dep 通过 notify 遍历了 dep.subs 通知每个 watcher 更新。
依赖收集
initState 时,对 computed 属性初始化时,触发 computed watcher 依赖收集
initState 时,对侦听属性初始化时,触发 user watcher 依赖收集
render()的过程,触发 render watcher 依赖收集
re-render 时,vm.render()再次执行,会移除所有 subs 中的 watcer 的订阅,重新赋值。
派发更新
组件中对响应的数据进行了修改,触发 setter 的逻辑
调用 dep.notify()
遍历所有的 subs(Watcher 实例),调用每一个 watcher 的 update 方法。
原理
当创建 Vue 实例时,vue 会遍历 data 选项的属性,利用 Object.defineProperty 为属性添加 getter 和 setter 对数据的读取进行劫持(getter 用来依赖收集,setter 用来派发更新),并且在内部追踪依赖,在属性被访问和修改时通知变化。
每个组件实例会有相应的 watcher 实例,会在组件渲染的过程中记录依赖的所有数据属性(进行依赖收集,还有 computed watcher,user watcher 实例),之后依赖项被改动时,setter 方法会通知依赖与此 data 的 watcher 实例重新计算(派发更新),从而使它关联的组件重新渲染。
一句话总结:
vue.js 采用数据劫持结合发布-订阅模式,通过 Object.defineproperty 来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发响应的监听回调
computed 的实现原理【原理题】
computed 本质是一个惰性求值的观察者。
computed 内部实现了一个惰性的 watcher,也就是 computed watcher,computed watcher 不会立刻求值,同时持有一个 dep 实例。
其内部通过 this.dirty 属性标记计算属性是否需要重新求值。
当 computed 的依赖状态发生改变时,就会通知这个惰性的 watcher,
computed watcher 通过 this.dep.subs.length 判断有没有订阅者,
有的话,会重新计算,然后对比新旧值,如果变化了,会重新渲染。 (Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性最终计算的值发生变化时才会触发渲染 watcher 重新渲染,本质上是一种优化。)
没有的话,仅仅把 this.dirty = true。 (当计算属性依赖于其他数据时,属性并不会立即重新计算,只有之后其他地方需要读取属性的时候,它才会真正计算,即具备 lazy(懒计算)特性。)
computed 和 watch 有什么区别及运用场景?【原理题】
区别
computed 计算属性 : 依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值。 【简单表达: 依赖缓存,依赖的值变化了才会自动变化】
watch 侦听器 : 更多的是「观察」的作用,无缓存性,类似于某些数据的监听回调,每当监听的数据变化时都会执行回调进行后续操作。 【简单表达:watch 监听数变化,无缓存依赖,监听的值变化了他就变化】
运用场景
当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算。 【不能放异步】当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。 【可以放异步处理】
为什么在 Vue3.0 采用了 Proxy,抛弃了 Object.defineProperty?【原理题】
Object.defineProperty 本身有一定的监控到数组下标变化的能力,但是在 Vue 中,从性能/体验的性价比考虑,尤大大就弃用了这个特性(Vue 为什么不能检测数组变动 )。为了解决这个问题,经过 vue 内部处理后可以使用以下几种方法来监听数组
|
由于只针对了以上 7 种方法进行了 hack 处理,所以其他数组的属性也是检测不到的,还是具有一定的局限性。
**Object.defineProperty 只能劫持对象的属性,**因此我们需要对每个对象的每个属性进行遍历。Vue 2.x 里,是通过 递归 + 遍历 data 对象来实现对数据的监控的,如果属性值也是对象那么需要深度遍历,显然如果能劫持一个完整的对象是才是更好的选择。
Proxy 可以劫持整个对象,并返回一个新的对象。Proxy 不仅可以代理对象,还可以代理数组。还可以代理动态增加的属性。
Vue 中的 key 到底有什么用?【原理题】
回答: 【简单表达:为了防止就地复用!】
key 是给每一个 vnode 的唯一 id,依靠 key,我们的 diff 操作可以更准确、更快速 (对于简单列表页渲染来说 diff 节点也更快,但会产生一些隐藏的副作用,比如可能不会产生过渡效果,或者在某些节点有绑定数据(表单)状态,会出现状态错位。)
diff 算法的过程中,先会进行新旧节点的首尾交叉对比,当无法匹配的时候会用新节点的 key 与旧节点进行比对,从而找到相应旧节点.
更准确 : 因为带 key 就不是就地复用了,在 sameNode 函数 a.key === b.key 对比中可以避免就地复用的情况。所以会更加准确,如果不加 key,会导致之前节点的状态被保留下来,会产生一系列的 bug。
更快速 : key 的唯一性可以被 Map 数据结构充分利用,相比于遍历查找的时间复杂度 O(n),Map 的时间复杂度仅仅为 O(1),源码如下:
|
谈一谈 nextTick 的原理【原理题】
JS 运行机制
JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个”任务队列”(task queue)。只要异步任务有了运行结果,就在”任务队列”之中放置一个事件。
一旦”执行栈”中的所有同步任务执行完毕,系统就会读取”任务队列”,看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
主线程不断重复上面的第三步。
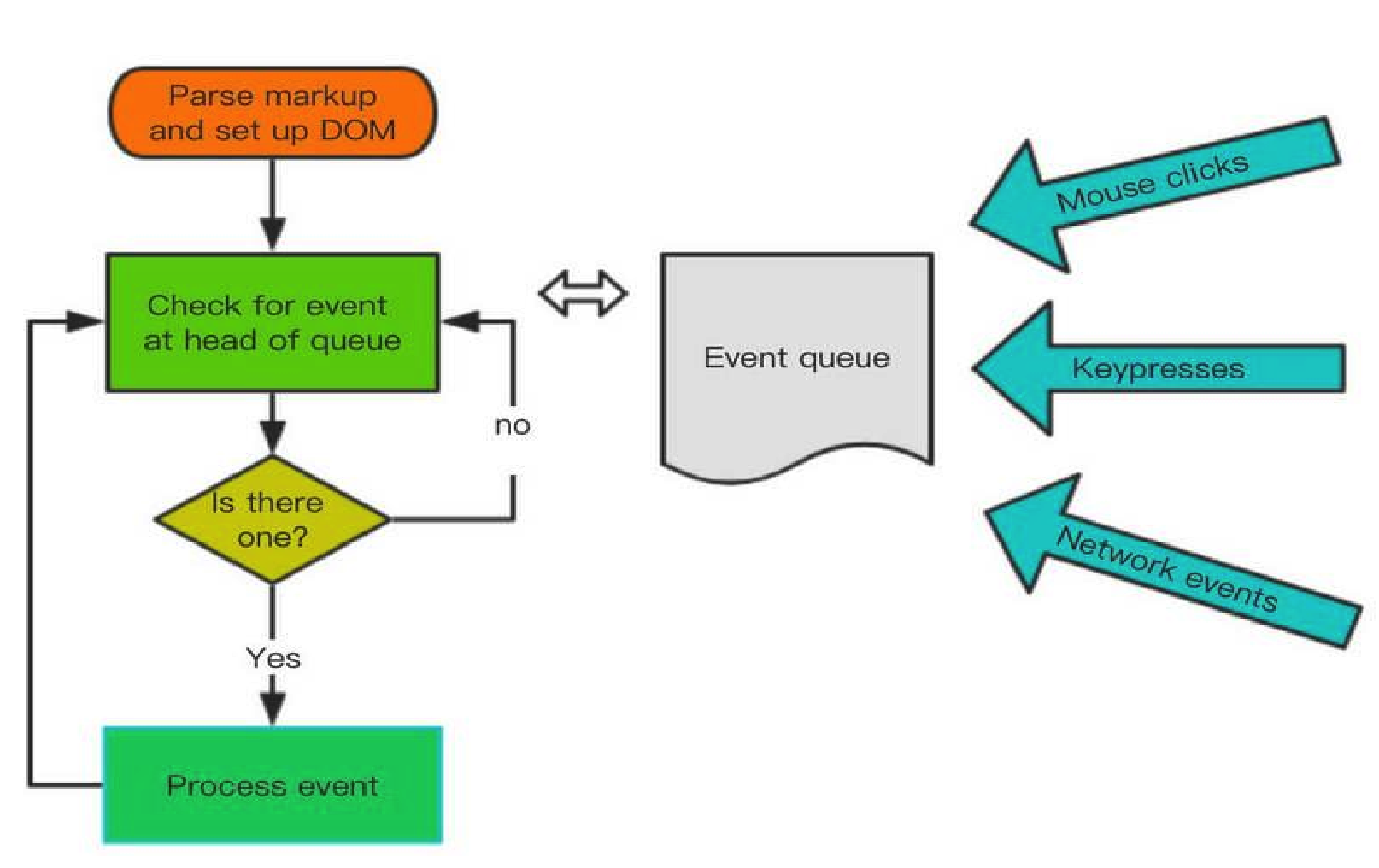 主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是 macro task 和 micro task,并且每个 macro task 结束后,都要清空所有的 micro task。
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是 macro task 和 micro task,并且每个 macro task 结束后,都要清空所有的 micro task。
|
在浏览器环境中 :
常见的 macro task 有 setTimeout、MessageChannel、postMessage、setImmediate
常见的 micro task 有 MutationObsever 和 Promise.then
异步更新队列
可能你还没有注意到,Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化,Vue 将开启一个队列,并缓冲在同一事件循环中发生的所有数据变更。
如果同一个 watcher 被多次触发,只会被推入到队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。
然后,在下一个的事件循环“tick”中,Vue 刷新队列并执行实际 (已去重的) 工作。
Vue 在内部对异步队列尝试使用原生的 Promise.then、MutationObserver 和 setImmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0) 代替。
在 vue2.5 的源码中,macrotask 降级的方案依次是:setImmediate、MessageChannel、setTimeout
vue 的 nextTick 方法的实现原理:
vue 用异步队列的方式来控制 DOM 更新和 nextTick 回调先后执行 microtask 因为其高优先级特性,能确保队列中的微任务在一次事件循环前被执行完毕考虑兼容问题,vue 做了 microtask 向 macrotask 的降级方案
如何判断 dom 更新完成后,再执行 nextTick 后的函数
实际上 dom 更新是实时的,所以不会阻塞,使用微任务后,可以保证所执行的方法在 dom 更新后
vue 是如何对数组方法进行变异的 ?【原理题】
我们先来看看源码
|
简单来说,Vue 通过原型拦截的方式重写了数组的 7 个方法,首先获取到这个数组的 ob,也就是它的 Observer 对象,如果有新的值,就调用 observeArray 对新的值进行监听,然后手动调用 notify,通知 render watcher,执行 update
Vue 组件 data 为什么必须是函数 ?【原理题】
new Vue()实例中,data 可以直接是一个对象,为什么在 vue 组件中,data 必须是一个函数呢?
因为组件是可以复用的,JS 里对象是引用关系,如果组件 data 是一个对象,那么子组件中的 data 属性值会互相污染,产生副作用。
所以一个组件的 data 选项必须是一个函数,因此每个实例可以维护一份被返回对象的独立的拷贝。new Vue 的实例是不会被复用的,因此不存在以上问题。
谈谈 Vue 事件机制,手写$on,$off,$emit,$once 【原理题】
Vue 事件机制 本质上就是 一个 发布-订阅 模式的实现。
|
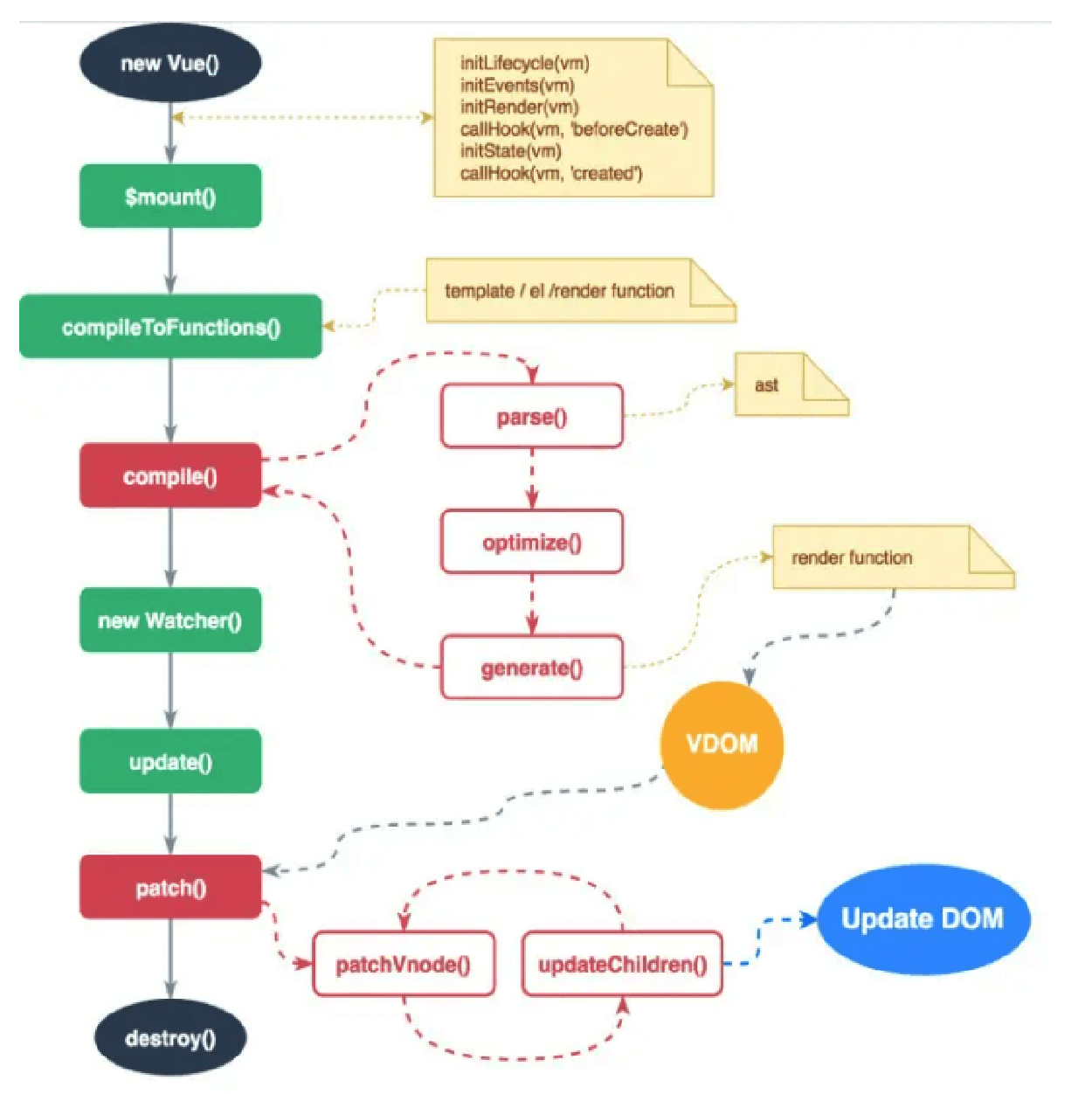
说说 Vue 的渲染过程 【原理题】
调用 compile 函数,生成 render 函数字符串 ,编译过程如下:
parse 函数解析 template,生成 ast(抽象语法树)
optimize 函数优化静态节点 (标记不需要每次都更新的内容,diff 算法会直接跳过静态节点,从而减少比较的过程,优化了 patch 的性能)
generate 函数生成 render 函数字符串
调用 new Watcher 函数,监听数据的变化,当数据发生变化时,Render 函数执行生成 vnode 对象
调用 patch 方法,对比新旧 vnode 对象,通过 DOM diff 算法,添加、修改、删除真正的 DOM 元素
聊聊 keep-alive 的实现原理和缓存策略 【原理题】
|
原理
获取 keep-alive 包裹着的第一个子组件对象及其组件名
根据设定的 include/exclude(如果有)进行条件匹配,决定是否缓存。不匹配,直接返回组件实例
根据组件 ID 和 tag 生成缓存 Key,并在缓存对象中查找是否已缓存过该组件实例。如果存在,直接取出缓存值并更新该 key 在 this.keys 中的位置(更新 key 的位置是实现 LRU 置换策略的关键)
在 this.cache 对象中存储该组件实例并保存 key 值,之后检查缓存的实例数量是否超过 max 的设置值,超过则根据 LRU 置换策略删除最近最久未使用的实例(即是下标为 0 的那个 key)
最后组件实例的 keepAlive 属性设置为 true,这个在渲染和执行被包裹组件的钩子函数会用到,这里不细说
LRU 缓存淘汰算法
LRU(Least recently used)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
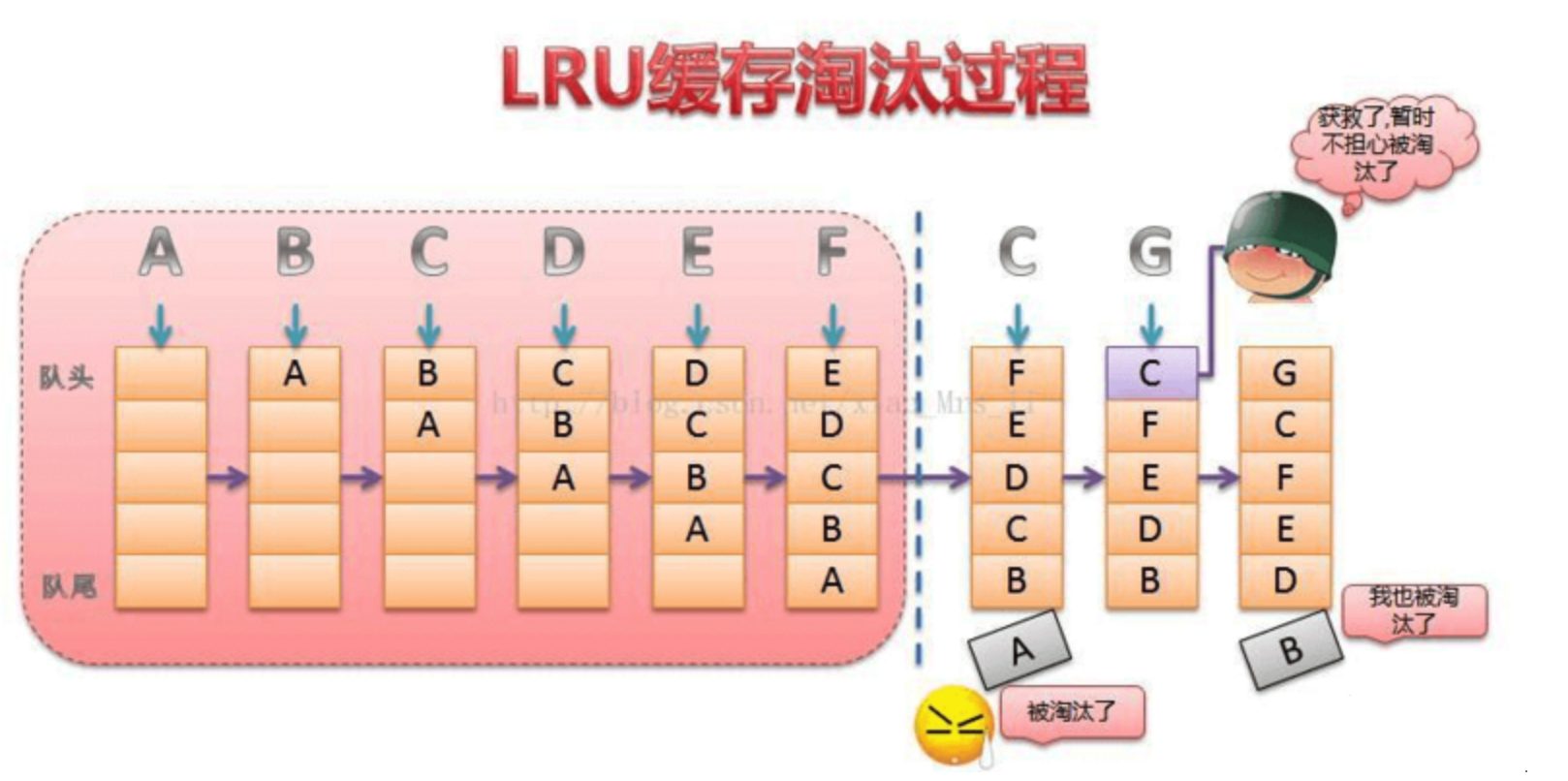
keep-alive 的实现正是用到了 LRU 策略,将最近访问的组件 push 到 this.keys 最后面,this.keys[0]也就是最久没被访问的组件,当缓存实例超过 max 设置值,删除 this.keys[0]
vm.$set()实现原理是什么? 【原理题】
受现代 JavaScript 的限制 (而且 Object.observe 也已经被废弃),Vue 无法检测到对象属性的添加或删除。
由于 Vue 会在初始化实例时对属性执行 getter/setter 转化,所以属性必须在 data 对象上存在才能让 Vue 将它转换为响应式的。
对于已经创建的实例,Vue 不允许动态添加根级别的响应式属性。但是,可以使用 Vue.set(object, propertyName, value) 方法向嵌套对象添加响应式属性。
那么 Vue 内部是如何解决对象新增属性不能响应的问题的呢?
|
如果目标是数组,使用 vue 实现的变异方法 splice 实现响应式
如果目标是对象,判断属性存在,即为响应式,直接赋值
如果 target 本身就不是响应式,直接赋值
如果属性不是响应式,则调用 defineReactive 方法进行响应式处理
Vue.use 方法的实现原理
Vue.use(plugin);
(1)参数
plugin
|
(2)用法
安装 Vue.js 插件。如果插件是一个对象,必须提供 install 方法。如果插件是一个函数,它会被作为 install 方法。调用 install 方法时,会将 Vue 作为参数传入。install 方法被同一个插件多次调用时,插件也只会被安装一次。
关于如何上开发 Vue 插件,请看这篇文章,非常简单,不用两分钟就看完:如何开发 Vue 插件?
(3)作用
注册插件,此时只需要调用 install 方法并将 Vue 作为参数传入即可。但在细节上有两部分逻辑要处理:
1、插件的类型,可以是 install 方法,也可以是一个包含 install 方法的对象。
2、插件只能被安装一次,保证插件列表中不能有重复的插件。
(4)实现
|
1、在 Vue 对象 上新增了 use 方法,并接收一个参数 plugin。
2、首先判断插件是不是已经别注册过,如果被注册过,则直接终止方法执行,此时只需要使用 indexOf 方法即可。
3、toArray 方法我们在就是将类数组转成真正的数组。使用 toArray 方法得到 arguments。除了第一个参数之外,剩余的所有参数将得到的列表赋值给 args,然后将 Vue 添加到 args 列表的最前面。这样做的目的是保证 install 方法被执行时第一个参数是 Vue,其余参数是注册插件时传入的参数。
4、由于 plugin 参数支持对象和函数类型,所以通过判断 plugin.install 和 plugin 哪个是函数,即可知用户使用哪种方式祖册的插件,然后执行用户编写的插件并将 args 作为参数传入。
5、最后,将插件添加到 installedPlugins 中,保证相同的插件不会反复被注册。
Vuex 的原理
vuex 本质是挂载一个名为 store 的 vm 组件在 Vue 的上下文环境
1.所以 this.$store 都是执行绑定的同一个 sotre
2.同时 state 因为在 vm 组件里面的 data, data 是使用new Vue()去创建一个 Vue 组件–所以具备响应式
为什么一定要用 mutation 中修改 state
state 修改的源码–mutation操作是调用_withCommit
|
- 本文作者: luckyship
- 本文链接: https://luckyship.github.io/2022/07/16/2022-07-16-vue-theory/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!